Kalaido Documentation
Kalaido Overview
Kalaido is built as a coordinated system of expert foundational models. The diffusion pipeline comprises a cascaded structure of two primary diffusion models (both operating at latent space) along with multiple style-LoRAs. This arrangement of MoE style architecture allows Kalaido to maximize frontier level aesthetics, text-rendering accuracy, stylistic consistency, and adherence to human preferences. We innovate at both the two key phases of training: pre-training and reinforcement learning, to improve the results and improve training efficiency. We curate highly specialized datasets from large corpus on Internet and filter out the highest signal images and prompts.
Technical Architecture
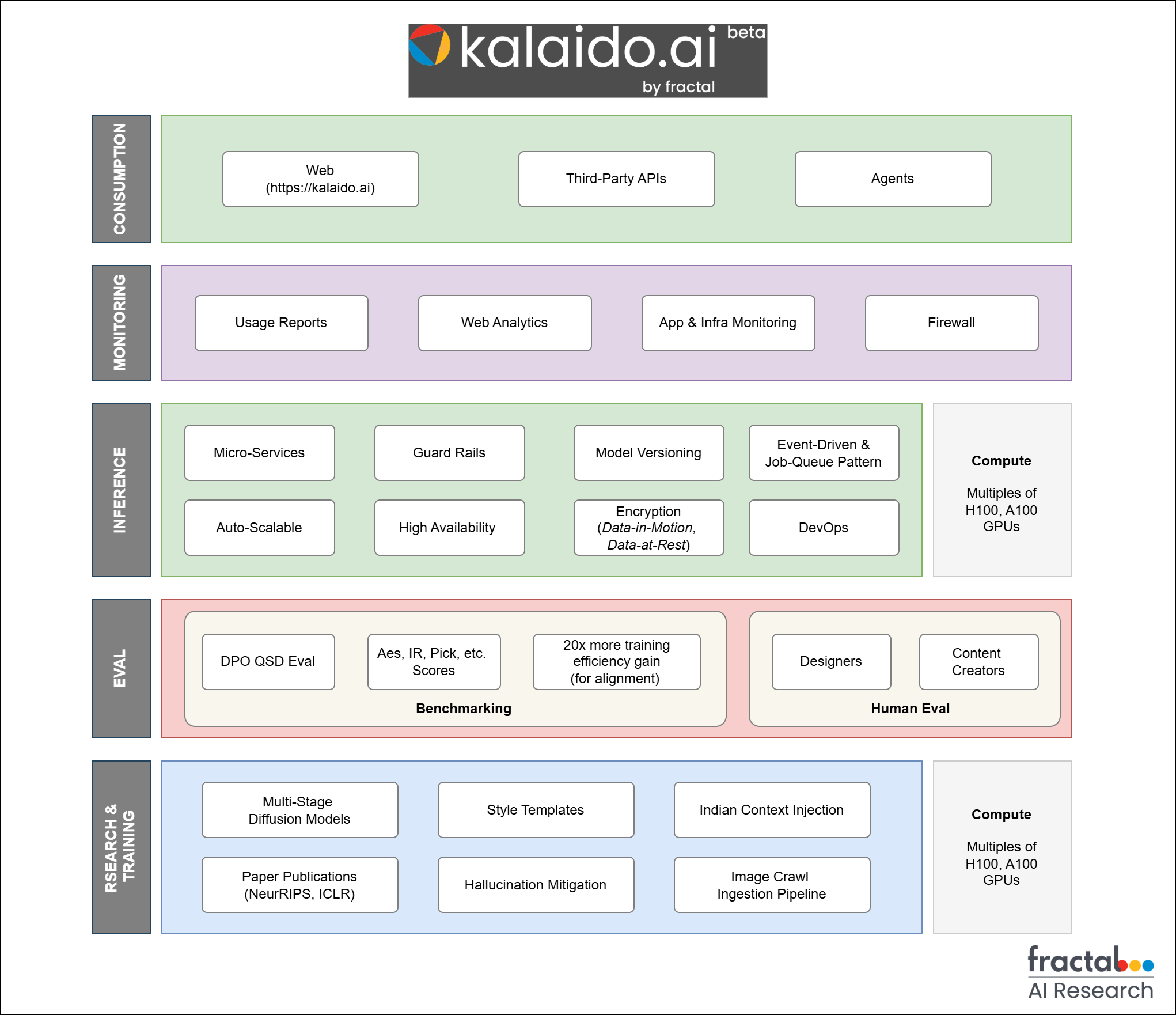
Benchmarking Details
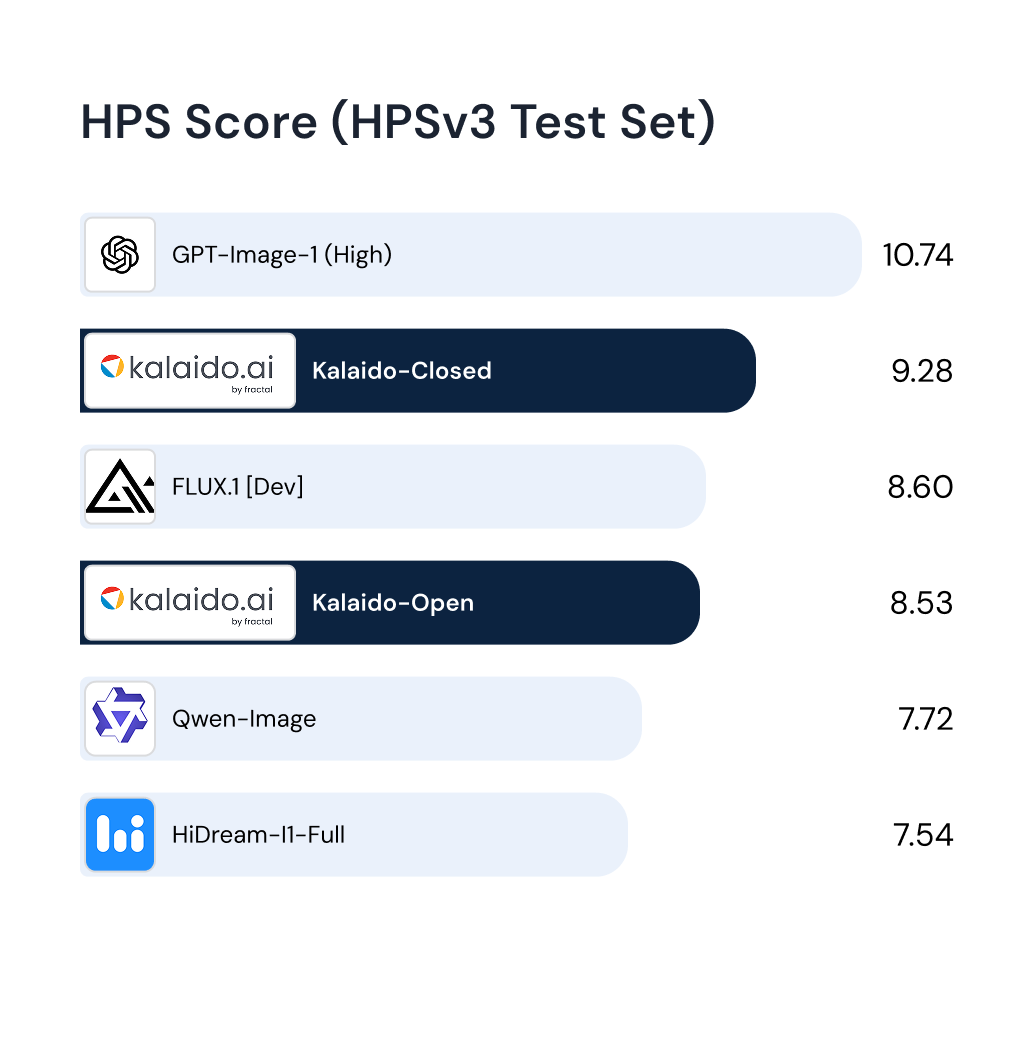
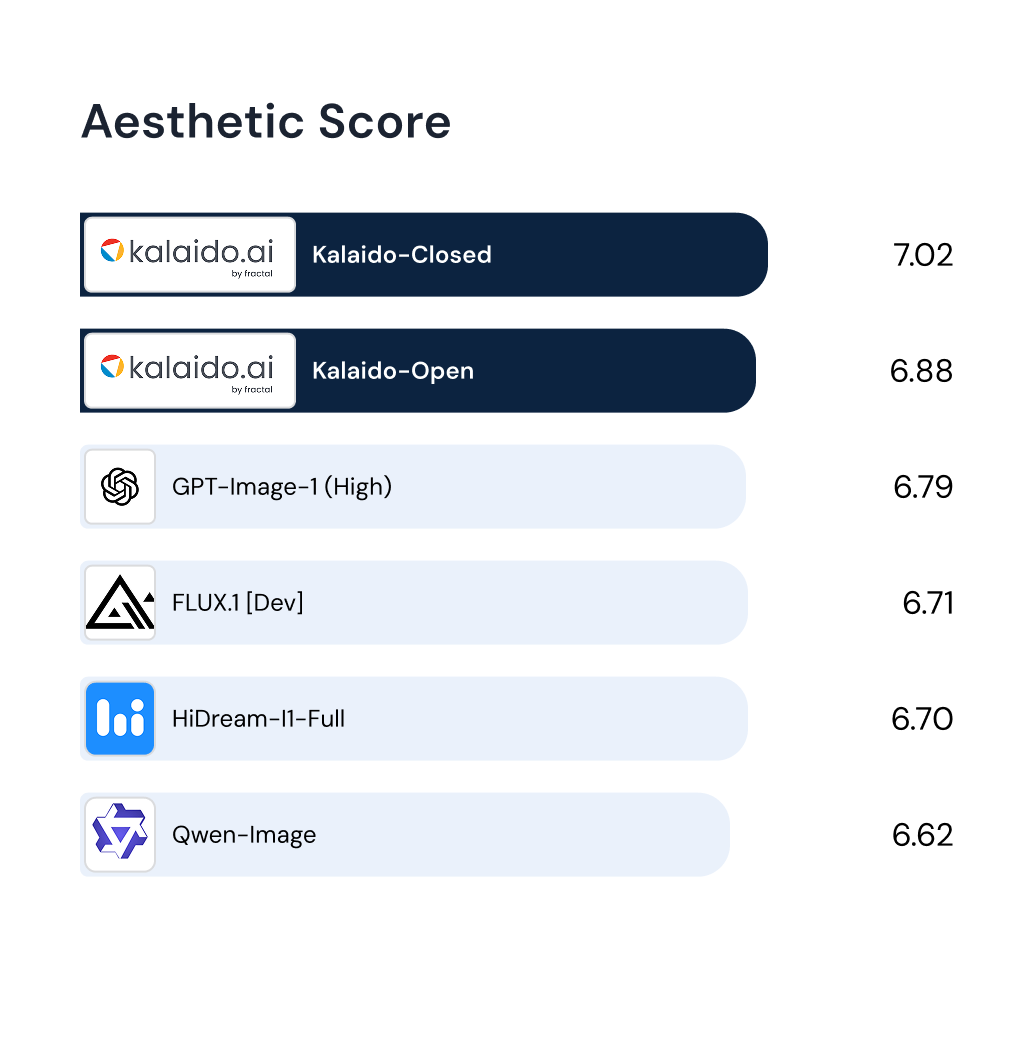
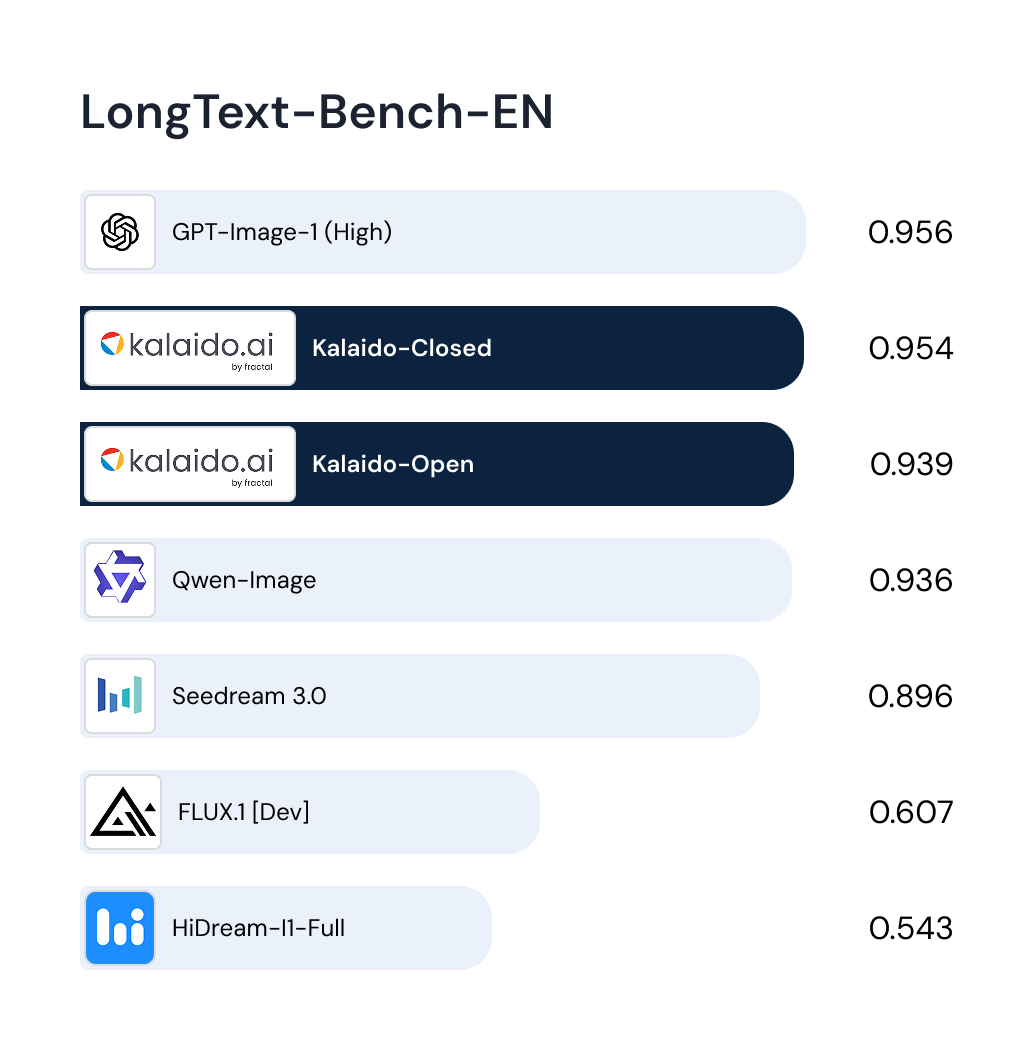


Paper Publication(s)
- Effective Text-to-Image alignment with Quality Aware Pair Ranking(NeurIPS’24 Adaptive Foundational Model)
- VISUAL PROMPTING METHODS FOR GPT-4V BASED ZERO-SHOT GRAPHIC LAYOUT DESIGN GENERATION(ICLR’24)